Combining MPC and RL for Real-World Control Systems
Discover how we merge Model Predictive Control (MPC) and Reinforcement Learning (RL) to create robust, adaptive systems that thrive in real-world scenarios. Learn about the challenges of the sim-to-real gap and our innovative solutions to ensure safety and reliability in AI-driven systems.
5/11/20261 min read
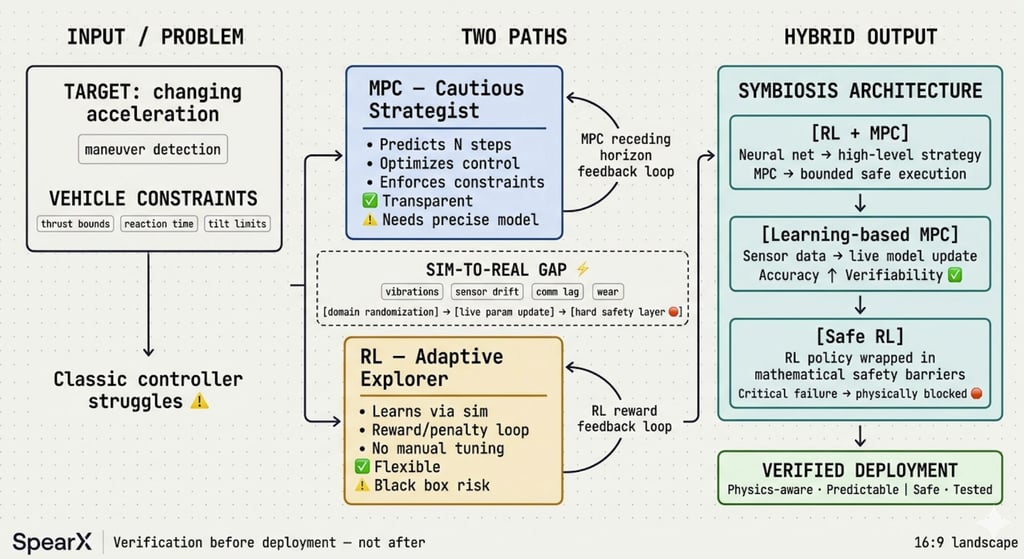
At SpearX, we face this question daily. When a target changes acceleration & our vehicle has strict limits on power, reaction time & maneuverability, classic controllers start to struggle.
We don't just debate theory-we build systems that must work in the real world.
So, we tested both paths: strict prediction and adaptive learning.
Here is what we learned - see below:
MPC (Model Predictive Control) is our cautious strategist. At every step, it calculates moves ahead, optimizing control while respecting hard physical limits: "stay within thrust bounds," "avoid excessive tilt," "compensate for actuator delays."
Why we use it: fully transparent, guarantees constraint compliance, robust to disturbances.
! The challenge: needs precise models and serious computing power in real-time.
Reinforcement Learning (RL) is our adaptive explorer. It does not solve equations. It learns a "policy" through rewards and penalties in simulation. It finds non-obvious maneuvers, handles complex scenarios, and adapts without manual tuning.
Why we explore it: flexible, excels in chaotic or poorly defined situations.
! Risk: "black box" behavior. Hard to explain decisions or guarantee safety outside trained data.
The Sim-to-Real Gap: Where We Spend Most of Our Time.
A policy that works perfectly in our digital lab often fails in field tests. Unmodeled vibrations, sensor drift, communication lag, mechanical wear-reality is messy.
At SpearX, we fight this with domain randomization, live parameter updates, and critically, hard safety layers that physically block the AI from crossing dangerous boundaries.
For us, testing is not optional. It is the only bridge between virtual success and physical reliability.
Our Engineering Verdict: Stop Choosing. Start Combining.
We are not picking "MPC or RL." We are building symbiosis:
• RL + MPC: Neural networks handle high-level strategy and uncertainty; classic controllers enforce safe, bounded execution.
• Learning-based MPC: Model parameters update live using sensor data-boosting accuracy without losing verifiability.
• Safe RL: Learning algorithms wrapped in mathematical barriers that make critical failures physically impossible.
Bottom Line:
The shift is not about replacing mathematics with AI.
It is about building hybrid loops where learning expands capability, and formal models guarantee predictability.
we believe: fast code means nothing if it ignores physics.
Verification must happen before deployment, not after!
Related : GEOCOM Co. LLC www.geocomco.eu DeepTechRnD www.deeptechrnd.eu SpearXAgro www.spearxagro.eu
Contacts
SpearX ↑ Strike with Precision
+359 877 620 210
D-U-N-S® 525540791


© 2025 - 2026. All rights reserved. SpearX Projects. Geocom Co. LLC





SpearX is an EU-Ukrainian company located in a strategic areas for R&D in UAV